Form: sounds and signs (gestures), less emphasis on writing which is a recording
The form to function continuum: sound/sign, words, sentences, meanings.
How to know a language
What do we know about language to make us claim that we know a language?
Knowledge of sound patterns (e.g. impossible consonant clusters, morphophonology.)
Knowledge of word patterns (wugs /woegz/ nazzes /nazzez/)
Knowledge of sentence patterns (ungrammatical sentences)
Meaning patterns (some sentences commit to certain ideas as predicates)
Language as a system
Generative
Rule-governed (Tacit and compositional)
Arbitrary (but standardized in order to make sense between communicating parties)
Generative system: Finite vocaulary $\Rightarrow$ new sentences
Outline of Proof: we can always take a part of a sentence and always add on something to it and still have it be valid.
A’s b
A’s b’s c
A’s b’s c’s d …
We can understand such expressions of arbitrary complexity because interpretation is compositional.
Rule-governed system: present even in colloquial/stigmatized dialects of English
(e.g. Singlish, African American English aka AAE)
unconscious/tacit rules
compositional as well
Arbitrary system: mapping of form to function is sometimes arbitrary (for individual morphemes to their meaning).
Problem Set 1
Question 1:
Generative
Consciously taught
Arbitrary
human languages
+
mostly -
+
programming languages
+
+
+
dog commands
-
+
+
morse code
+
+
+
chinese characters
-
+
+
bird song
+
-
+
art
+
-
+
emoji
-
-
-
Emoji not really arbitrary.
Chinese characters not flexible enough to be generative.
Question 2:
It supports the idea that sign/sound and meaning mapping is arbitrary.
If it were not, then there would be more consistency between the onomatopoeia cross-culturally,
but in many cases they have no similarities at all, especially for the sounds of dog, pig.
But it is not completely arbitrary as patterns can be still seen across.
cat and cow always start with nasals.
sheep mostly start with [m], but [b] is sonorant also
[h] and [k] and post-palatal
Likely due to brain picking up different sounds.
Lecture 2: Properties and Organization of Words
Lexicon: Mental table of mapping between forms and their meanings
Lexical categories: parts of speech
nouns [N]
pronouns: no fixed reference
proper names
verbs [V]
adjectives [ADJ]
adverbs [ADV]
prepositions [P]
Determiners [Det] e.g. a, the, this
Conjunction [Conj] e.g. and, but, or
Auxiliary Verb [Aux] e.g. modal verbs
Content words:
relatively easy to define,
open-class
usually [N, V, ADJ, ADV]
Function words:
grammatical functions
closed-class
usually [Det, Conj, P, Aux, pronouns]
Relationships between the content words
Psychologically we treat content and function words differently (as can be seen from aphasics)
Content words more likely to switch
Content words less likely to omit (children learn them first)
Morphemes
Morphemes are the smallest meaningful units in the language.
Hypothesis: Morphemes are stored in the lexicon
implication: single mapping of morpheme form to function
counterexample: -er has multiple meanings (e.g. teacher vs letter)
Bound morphemes
Bound morphemes (cannot exist on their own) vs free morphemes (can)
Bound morphemes often have rules (see distribution) on what they can bind to.
The same morpheme can take on multiple meanings (e.g. the “un-“ prefix)
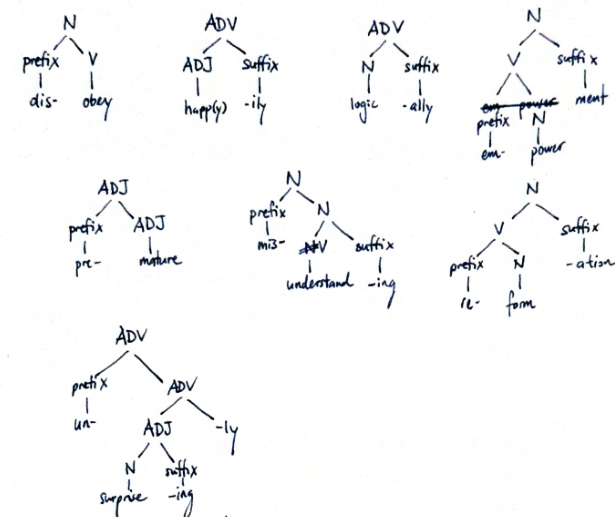
This gives rise to morphological structure trees:
Problem Set 2
dis-obey
happ-ily
logic-ally
WRONG: logic-al-ly
em-power-ment
pre-mature
mis-understand-ing
re-form-ation
un-surpris-ing-ly
see image for structure trees
Zulu nouns and verbs:
a) singular “um”, plural “aba”
b) “a”
c) “i” is a suffix for noun class
d) “baz”, “fund”
Lecture 3: Properties and Organization of Words
Alphabet $\Sigma$: finite set of symbols
String: finite sequence of symbols from $\Sigma$
Language: set of strings
Length: Number of symbols in a string. (if $a$ = “10110”, $|a| = 5$)
Empty string: $\Lambda$. ($|\Lambda
= 0$)
Infinite Language $\Sigma^*$: is the language of all possible strings over $\Sigma$.
Any language $L$ of $\Sigma$ is a subset of $\Sigma^*$.
Empty Language $\emptyset$: language with no strings.
Concatenation:
Concatenation of strings:
$x$ CONCAT $y$ = $xy$
$x\Lambda = x = \Lambda x$ ($\Lambda$ is identity element)
$xx^{k} = x^{k+1}$
$x^0 = \Lambda$
Concatenation of languages:
$L_1 L_2 = {xy \mid x \in L_1 \vee y \in L_2}$.
$L_1 L_2 \neq L_2 L_1$ as $xy \neq yx$ (non-commutative).
$LL_k = L^{k+1}$
Closure: $L^* = \Cup_{i=0}^\infty L_i$.
Computational questions
Generation: How do we generate the sentences of a language?
Grammar: rules of production for a language
Recognition: How do we recognize if a string $x \in L$?
We don’t consider this programmatically to prevent the influence of a specific PL.
Describe recognition in a computing machine/automatron that isn’t a language
Specification: What’s the best way to specify a language $L$?
Providing an automaton that recognizes
Providing a grammar that generates
Intensional formal definition
None of the above are “best”!
Must show the correspondence between them.
Language Classes
Complexity of languages
Regular languages $\subset$ Context-free Languages
Regular language: A language that can be specified by an FSM/FA
Automata: Recognizes tokens. Specifies a symbol recognition machine
Regular expressions: algebraic notation to generate languages
Context Free Grammars (CFG): Formation of statements from tokens.
Turing Machines: Most powerful form of automata.
Automata
State
Finite Automaton (FA): Automaton with a finite number of states
Transition
State transition diagrams
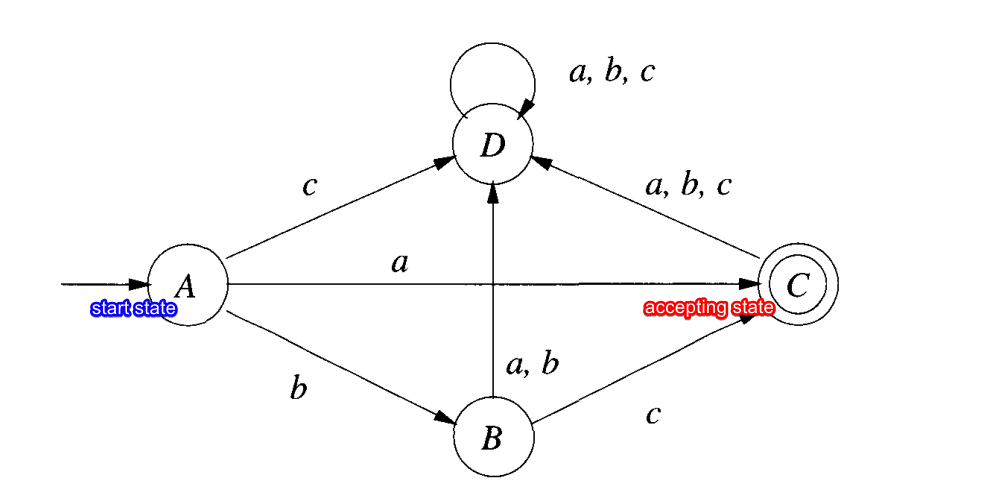
Start state
Accepting state
Sink
Accepting sink
Non-accepting sink (can be removed together with all it’s incoming links)
Note that $D$ here is a sink, a state which once you enter you can’t leave.
Distinguishability
A string $x$ and $y$ are distinguishable from each other
if you can have another string $z$ such that either
$xz \in L \wedge yz \notin L$
OR $yz \in L \wedge xz \notin L$
note that it is allowed for $x, z \notin L$.
Problem Set 3
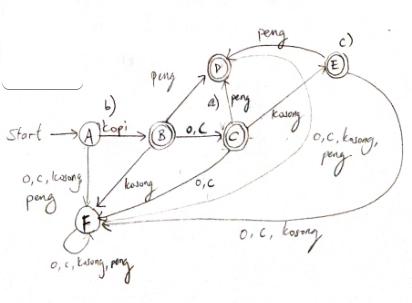
FSM
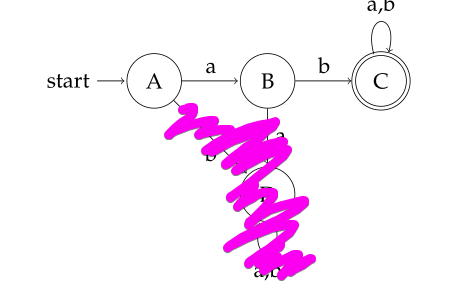
a) Accept: ${ab, aba, abb}$. Reject: ${a, b, bb}$
b) Any sequence of a and b preceded with a prefix $ab$.
c)
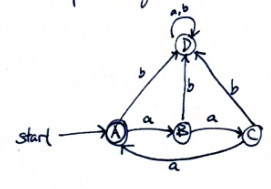
$\Sigma = {kopi, o, c, peng, kosong}$
b) Add $teh$ link from $A$ to $B$. For all other states, add a $teh$ link to $F$.
c) the diagram above allows for “kopi ${o,c}$ kosong peng”.
always do the simplest diagram to generate.
Lecture 4: Context Free Grammars
Rules $S$ can rewrite a grammatical string. These are rewrite rules
e.g. Let $S$ be a variable for any grammaticl string in $L_{a^n b^n}$.
In this language, we have the rule:
\[S \rightarrow a S b\]
We also need at least one pattern that can be $S$ to start generating all the possible strings.
\[S \rightarrow \Lambda\]
Dyck language
$S \rightarrow \Lambda$
$S \rightarrow ( S )$
$S \rightarrow S S $
CFG
non-terminal symbols $S$
terminal symbols (lexicon)
rewrite rules (phrase-structure rules)
NT symbols $\mapsto$ seq of T or NT symbols
Derivation, parses, trees
string input
back into grammatical units
TREES
in a tree:
$S$ is root
each edge create using rewrite rule
non-terminal symbols have daughters created by rewrite rules
terminal symbols no children
string is sequence of terminal nodes
Structural ambiguity
\[0 \times 1 + 1 = ?\]
same string can have diff parsed structures
Weakly equivalent grammars
If 2 grammars can create exact same lexicon but have diff parse trees/derivations,
they are called weakly equivalent grammars.
Which then should we go with when describing grammar?
how naturally can the grammars be extended to cover other phenomena?
How many rules are being added?
Constituency tests
Conjunction test “A and B”
Replacement test “Can B be replaced by a pronoun?” (he/his/she/her/it, one, and other complementizers e.g. there, that)
Ellipsis test “Can B be left out i.e. $A - B$”
Dislocation test? Yodaspeak “$B, A - B$”
an acceptable adjustment to make during constituency tests: “unpacking” verbs.
e.g. crossed $\rightarrow$ did cross (which has auxiliary verb “did”)
Ambiguity and constituency
Click studies
Merrill Garrett
record several sentence with identical phrases
click sounds on the same word on every one of such phrases
where did you hear the click?
surprisingly, many variations between different sentences though the phrases are identical.
Evidence that
humans tend to displace clicks onto major constituent boundaries
position of clicks on such boundaries are guessed more accurately
than the cliks interrupting constituent phrases.
Problem Set 4
CFG for $L_{kopi}$.
S -> kopi
S -> kopi X
X -> MILK
X -> MILK VER
MILK -> o
MILK -> c
VER -> peng
VER -> kosong
Constituency tests
“You should buy some ETFs before you retire.”
You should buy some ETFs and read some books before you retire (ok)
You should (*[Pronoun/Complementizer]) before you retire (NOPE)
You should before you retire (ok)
Buy some ETFs, you should before you retire
“I baked this cake for Grace”
I baked this cake for Grace and for John
I baked this cake there
I baked this cake
For Grace, I baked this cake
“I’m excited for Myunghye to come to Singapore.”
I’m excited for Myunghye and for John to come to Singapore
I’m excited then to come to Singapore
I’m excited to come to Singapore (??)
For Myunghye, I’m excited to come to Singapore (??)
Korean example
X -> S P
S -> “Chelsu ga”
P -> “uletta”
P -> “gu sagwa lul boatta”
P -> “Sunhee lul jonkyunghanda”
P -> “gu gemun gae lul joahanda”
IGNORE THE BELOW
P -> O Vtrans
P -> Vintrans
O -> “Sunhee lul”
O -> “gu sagwa lul”
O -> “gu gemun gae lul”
Lecture 5: Reflexes of structure
Parse trees: static representation of a string/sentence.
i.e. if a legal parse tree exists we can verify that string/sentence is grammatical.
Constituency tests recap
Conjunction test $XP \rightarrow XP \text{ and } XP$ or $X \rightarrow X \text{ and } X$
Ellipsis test $VP \rightarrow \Lambda$
Replacement test $NP \rightarrow \text{Pronoun}$ or $PP \rightarrow \text{there}$
Transformational grammar
Movement is applied to trees first generated by a basic CFG.
This can be seen in the treatment of Question formation in English.
e.g. in Chinese, add the question tag “ma1”.
e.g. in English, “She will go.” $\rightarrow$ “Will she go?”
a. I saw myself in the mirror.
b. * Myself saw me in the mirror.
c. I showed the monkey himself in the mirror.
d. * I showed himself the monkey in the mirror. [No other 3SG entities introduced before “myself”]
a) Hypothesis 1. Reflexive pronouns must refer to an entity already introduced in the sentence.
a. Myself refers to I
b. Myself cannot refer to me.
[No entities introduced before “myself”]
c. himself refers to the monkey
d. himself cannot refer to the monkey because after.
himself doesn’t refer to I (mismatch), and no other 3SG entities introduced before ‘himself’.
b) Hypothesis 2. Reflexive pronouns must refer to an entity already introduced in the enclosing clause but not in a child constituent.
i.e. the reflexive pronoun must be a sibling of the entity it is referring to
a. herself refers to Carla
b. herself cannot refer to Carla as Carla is not a sibling of “herself” [about Carla is a nested PP of the NP “A book about Carla”]
herself doesn’t refer to a book because book does not use gendered pronouns.
c. themselves refers to John’s teachers (3PL)
d. himself cannot refer to John as John is not a sibling of “himself” [John’s is a nested AdjP of the NP “John’s teachers”]
himself doesn’t refer to John’s teachers (mismatch) as no other sibling 3SG entities before himself.
c) Hypothesis 3. Reflexive pronouns must refer to an NP in the enclosing clause but not in a parent constituent.
a. herself refers to Mary
b. myself doesn’t refer to I. (I not closest to “myself”)
myself doesn’t refer to Mary (mismatch, 1SG vs 3SG)
Ditransitive verbs
Lecture 6 [Week 8]: Quantification
Different relationships between sets
Quantification determiners in natural language all conservative
Syllogism
Pattern of reasoning from premises to conclusion.
Replacing the non-logical parts: Reasoning still holds (valid).
Validity of syllogisms depend on the meaning of the sentences’
logical parts (quantification determiners).
Example of quantification determiner: some, all, few, etc.
Set theory
Venn diagrams / Eulerian Circles: Originated from Euler.
Every A is B
No A is B
Some A is B
Some A is not B
Set notation
Cardinality: size of a set
Quantificational Determiners
Describe relations between sets.
every(A)(B) iff $A \subseteq B$ are the truth conditions for “Every A is B”.
a/some(A)(B) iff $A \cap B \neq \null$ are the truth conditions for “Some A is B”.
Take a quantificational determiner $Q$
Downward entailment
Sentence S refers to set X
Let S’ be S replaced with X’ st $X’ \subset X$.
If S’ still true for ANY CHOICE OF X’ then S’ is downward entailing.
Conservative
For any sets $A, B$, $Q(A)(B) \Leftrightarrow Q(A)(A \cap B)$.
e.g. every. “Every dog swims” $\Leftrightarrow$ “Every dog swims and is a dog”.
Lecture 7 [Week 9]: Negative Polarity Items
NPI example:
Edwin has talked to any of the students
Edwin hasn’t talked to any of the students
any: The NPI
hasn’t: The licensor of the NPI.
To license the use of a token is to make the token in that context valid.
Negative polarity dependency is … associated with …:
determiners (any)
sentence adverbs (yet/ever)
verb phrases (lift a finger)
intransitive verbs (budge)
transitive verbs (faze)
modals (need/dare)
particles (either)
Positive polarity item (PPI) example:
Edwin has talked to one of the students
Edwin hasn’t talked to one of the students
= There is a student Edwin didn’t talk to
$\neq$ Its false that Edwin talked to a student
What are NPI licensors?
Hyp 1: Negations and negative quantifiers.
Examples:
John agreed to eat any of the bagels.
ACTUALLY isn’t this fine??
John didn’t agree to eat any of the bagels
John refused to eat any of the bagels
problems:
negation can be symmetric. semantic decomposition of “refused” and “didn’t agree” is arbitrary
no negation needed!
Everyone who ever ate bagels loved them.
If you ever eat bagels you will love them.
Hyp 2: Downward entailing environments.
Sara read any article.
Sara read one article $\Leftarrow$ Sara read $N$ articles (upward entailing)
Sara read one article $\nRightarrow$ Sara read $N$ articles (not downward entailing)
I don’t think Sara read any article
IDT Sara read one article $\nLeftarrow$ IDT Sara read $N$ articles (not upward entailing)
I don’t think Sara read one article $\Rightarrow$ IDT Sara read $N$ articles (downward entailing)
Examples of DE environments:
Negated environments
Must demonstrate!
Negation is a common licensor as it flips entailment relations
If clause of conditionals: If $X \Rightarrow$ If $X’$ where $X’ \subseteq X$
First argument $A$ of every
Consider each environment $A, B$ of $Q(A)(B)$ separately to see if it fulfils DE.
Proof that A of every$(A)(B)$ is DE
Let $A’$ be any proper subset of A.
By definition of every$(A)(B)$, $A \subseteq B$.
Since $A’ \subset A \subseteq B$, we get $A’ \subseteq B \Rightarrow$ every$(A)(B)$ due to iff.
Strong NPIs
Downward entailment insufficient, negation is required too.
e.g. “in weeks”
John saw Mary in weeks.
John didn’t see Mary in weeks.
If John does see Mary in weeks, then he will be mad.
DE on If’s A.
Less than 4 ppl have seen me in weeks.
DE on count
Everyone here has seen me in weeks.
DE on every’s A.
Conclusion
NPI are licensed by downward entailment
Lecture 8 [Week 10]: Quantification and Triviality
Exceptives
The primary function of exceptive removes certain individual from set A in the relationship $R(A)(B)$
e.g. Every student but John came to the party $\Rightarrow {S \backslash John } \subseteq P, John \notin P$
e.g. No student but John came to the party $\Rightarrow {S \backslash John } \cap P = \emptyset, John \in P$
Truth conditions of exceptives
Hence the truth conds of $Q$[$A$ except/but $x$]$B$ is
$Q(A \backslash x)(B)$ is true
$Q(A)(B)$ is false
Note that because of these strict truth conds many quantifiers cannot take exceptives. e.g.
*Some student but John came.
*One student but John came.
*At least 2 students but John came.
These are all determiners but bc they don’t follow the truth conditions of exceptives.
Note that they are all upward entailing, which will lead to a contradicition. because $A \backslash x \subseteq A$
Grammaticality of trivialities
But not all contradictions are ungrammatical.
Contradiciton: cannot be true in any world
Tautology: true in all possible worlds
Contingency: a sentence is true in some worlds but not others
Contradictions and Tautologies are both Trivialities, e.g. “war is war”, “A is either true or not true”. But these are not ungrammatical.
L-triviality
A sentence $S$ is L-trivial iff $S$ is a triviality under all content word substitutions.
Logical triviality: triviality of the statement itself. L-triviality is stricter than triviality and must assume each part of the statement is different variable.
It is sunny or not sunny $\Rightarrow$ It is $P$ or it is not $Q$ (not a logical contradiction)
As opposed to:
Some student but John came $\Rightarrow$ Some $A$ except $x$ is $B$ (contradiction
as $A \backslash {x} \cap B \neq \emptyset$ is true but $A \cap B \neq \emptyset$ is also true,
which is said to be false by the exceptive but!)
Gajewski’s conjecture
L-trivial sentences are ungrammatical.
By virtue of its logical words, if a sentence cannot communicate any contingencies it is ungrammatical.
There-constructions
(note: this “there” is not the place-preposition referring to a location, it implies existence)
Existential there-constructions are limited to some quantifiers:
*There is every green rose
*There is all green roses
*There is not all green roses
Truth condition for “There is/are Q A”: $Q(A)(D)$ where $D$ is the universe.
e.g. There is no green roses $\Rightarrow$ no(green rose)(universe) is true $A \cap D = \emptyset$. This is neither a tautology or a contradiction
e.g. *There is every green roses $\Rightarrow$ every(green rose)(universe) is always true as $A \subseteq D$ is a tautology
Reflexivity
Reflexive: $Q(A)(A)$ always true
irreflexive: $Q(A)(A)$ always false
We can conclude grammatical There-constructions must necessarily be neither reflexive nor irreflexive