File type: a description of the information contained in the file (based on a certain format etc.)
File extension: part of the file name after the dot, used in Windows etc. to identify file type
Magic number: set of k-byte (usually $k=2$) identifiers at start of file.
Access Control List (ACL):
Minimal ACL (same as permission bits) – drwxr--r-- (owner - group - universe)
Owner: creator of file
Group: set of users who need same access to file
Universe: all other users
Extended ACL (added named users/group) – getfacl
File system architecture
File data structure options:
Array of bytes (each has specific offset from the start.)
Fixed length records (array of records that can grow/shrink) similar to fixed memory partition, internal fragmentation
Variable length records (flexible but harder to locate) similar to variable-size memory partition, external fragmentation
Access methods:
Sequential access: read in order, starting from beginning (can be rewound but not instantly access a location)
Random access: access any byte directly
Read(offset): explicitly state position to access
Seek(offset): special operation move cursor to new location in file
Windows, Linux use seek (lseek)
Random access is a special case of direct access where 1 record == 1 byte
Direct access: access any record directly
Used for fixed length records
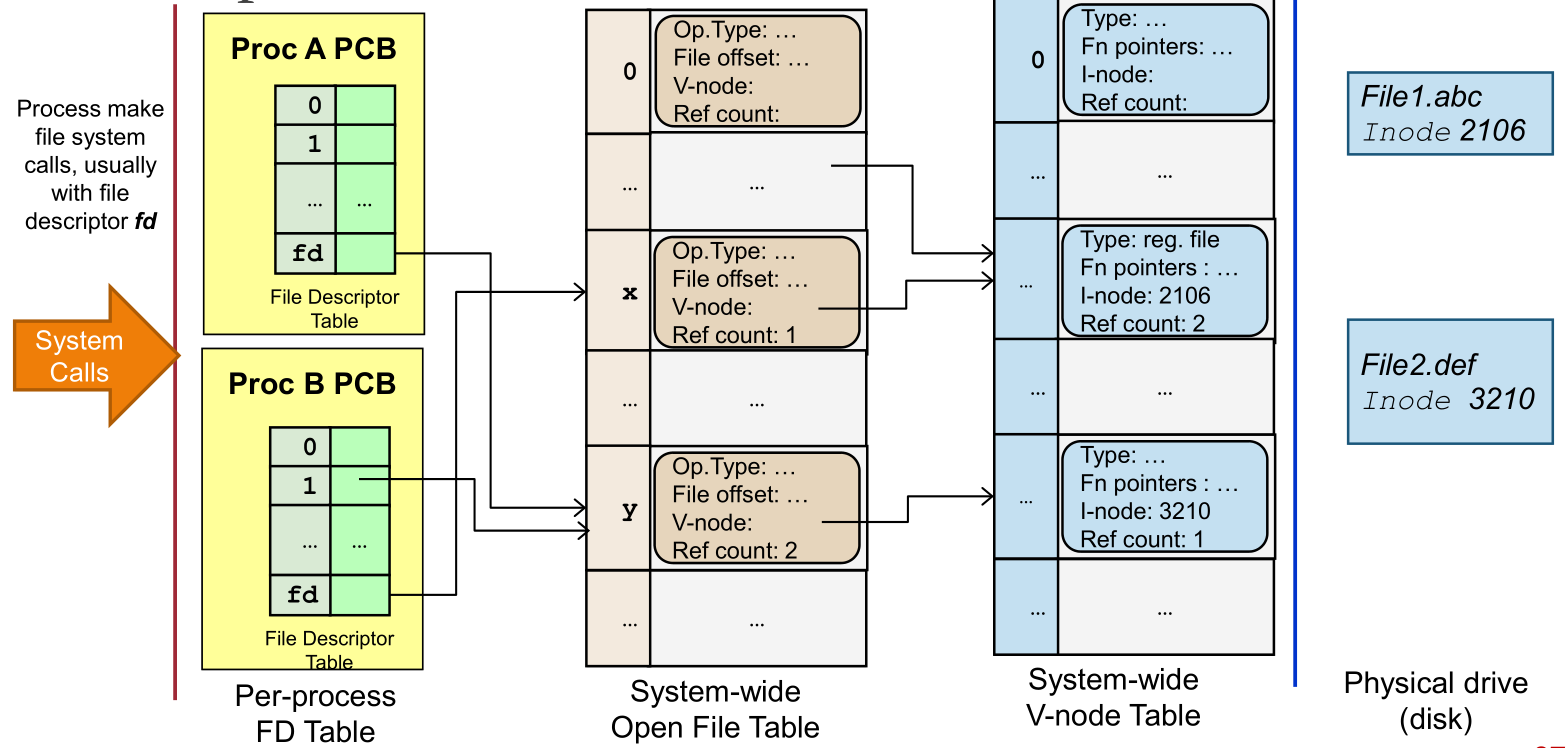
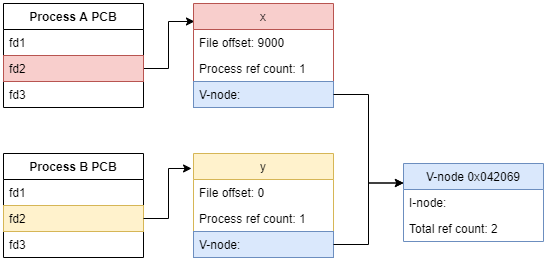
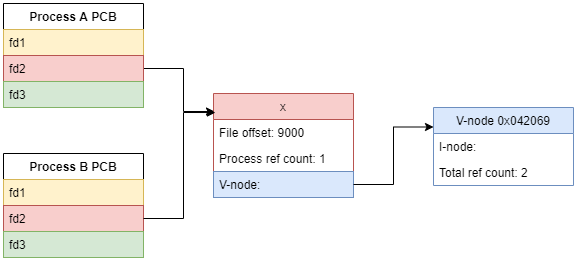
The operation of open has an important role to keep references to the all the pointers necessary to access a physical disk, removing the need to access the full filepath every time. It also tracks the file offset.
File operations:
Operation
Description
Create
New file, no data
Open
Prepare necessary information for later operations
Read
Read data from current position
Write
Write data to current position
Seek
Move position to a new location
Truncate
Remove data from current position to end of file
Current position is maintained by the file pointer.
Via system calls (protection, concurrent and efficient access)
File descriptor should link to the following information for each opened file:
File pointer to system-wide open-file table entry
File information (3 tables):
Per-process open-file table
Each PCB contains a file descriptor (fd) table
Each fd entry stores a pointer to an entry in sys-wide open-file table
Open files for a process
Each entry points to the system-wide open-file table
Minimum 3 file descriptors: stdin, stdout, stderr
System-wide open-file table (accessed on open syscall)