to understand and optimize the performance of parallel programs.
Concurrency vs Parallelism
Concurrency
Parallelism
Tasks have overlapping time periods
Tasks can run simultaneously exactly at the same time
Interleaiving ok
Interleaving not happening
Due to the core’s pipeline, simultaneous execution is possible at the level of the core
Multiple data used by instruction
Multiple instruction can happen at the same time
Multiple threads can run at the same time
Forms of parallelism
Type of parallelism
Description
Superscalar
Multiple instructions from same thread at same time
Multithreading
Multiple threads execute at same time
Multiprocessing
Multiple threads/processes execute at same time
Bit-level parallelism
Since we mostly operate on multiple bits at once in a single operation, we often have bit-level parallelism.
We often operate on words.
Word size:
Unit of transfer between processor and memory
size of a memory addr
size of an int
size of a single precision float
Instruction-level parallelism
Across time
Across space
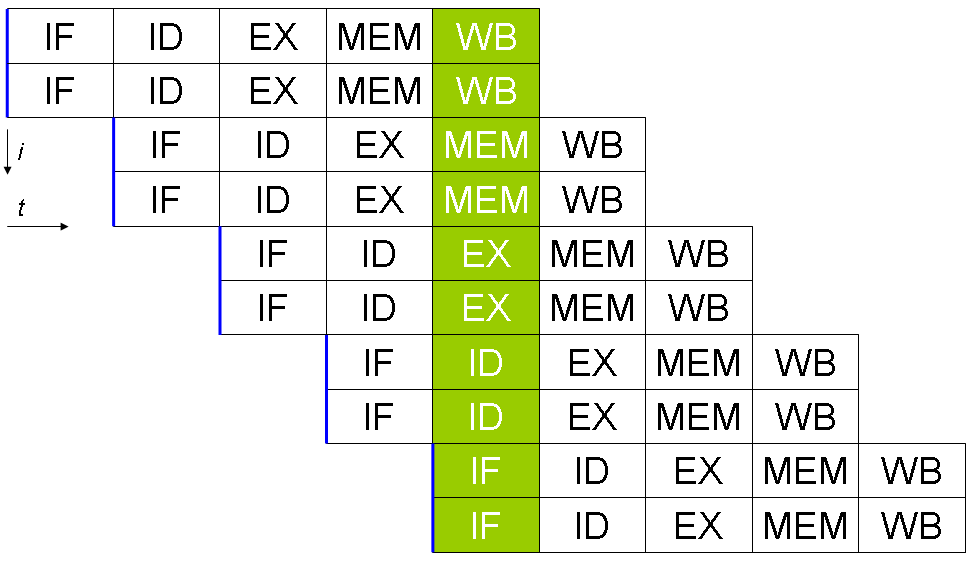
Pipelining
Superscalar
Pipelineing
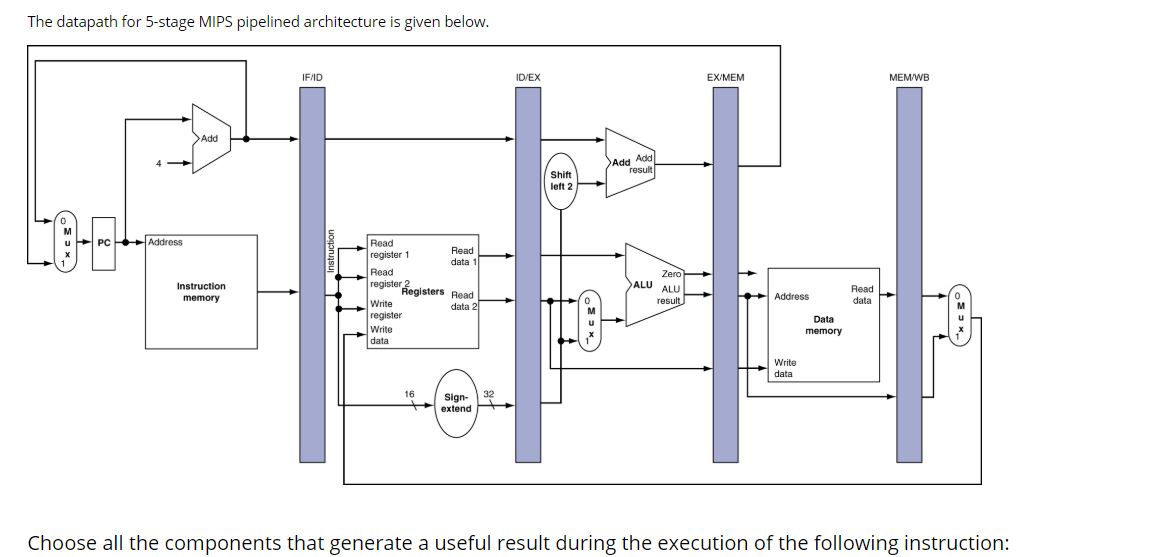
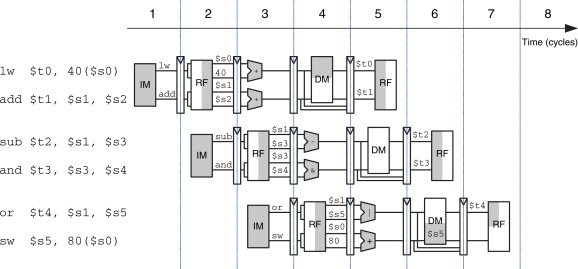
Fetch - Decode - Execute - (Mem) - Write-back
Multiple instruction occupy different stages in one clock cycle
Provided no data/control dependencies
Max speedup is linked to the number of pipeline stages.
Problems:
Instruction dependency problems
“Bubbles”: the pipeline gets blocked by dependencies etc or repeat work.
Hazards: due to the control flow we don’t have the correct data at the time we need it
Speculation
Out of order execution
Towards 2000 the gains in efficiency from increasing number of stages tapered off
Superscalar
Duplicates all or some the stages of the pipeline. Instead of 1 instruction in the fetch stage,
we can have 2 instructions in the stage at the pipeline.
All the instructions coming the same thread in the same core.
Processor has to find independent instruction to run simultaneously
Finding instructions that can run in parallel on instruction level is very difficult.
Scheduling too challenging.
Summary:
The speedup is still bottlenecked by the instruction execution, which all comes from the same thread.
Thread-level parallelism
While software can run multiple threads concurrently, the processor can run multiple threads in parallel!
SMT (Simultaneous multithreading) at the hardware level
Hyperthreading (Proprietary to Intel)
no need for context switch
2 threads ready to fire instruction at the same time
interleaving instructions
Implementations
Fine-grained multithreading: switch threads per instruction
Coarse-grained multithreading: switch threads per stall (types of stalls below)
Time-slice MT (switch on predefined time-slide)
Switch-on-event MT (switch if processor is waiting for event)
SMT: scheduling insn from different threads in one cycle
Processors with up to 8 hardware threads
one core may have a few hardware threads
thread = “logical cores”
The processor can also have multiple cores!
Core-level parallelism
These days we put multiple cores in the same processor.
Totally independent execution
Different contexts
Each core has all stages of pipeline, different registers etc.
Flynn’s Parallel Architecture Taxonomy
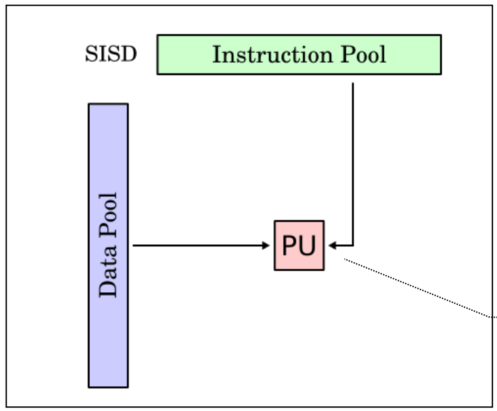
SISD (Single insn single data)
One stream of instruction
One instruction one piece of data
Uniprocessors
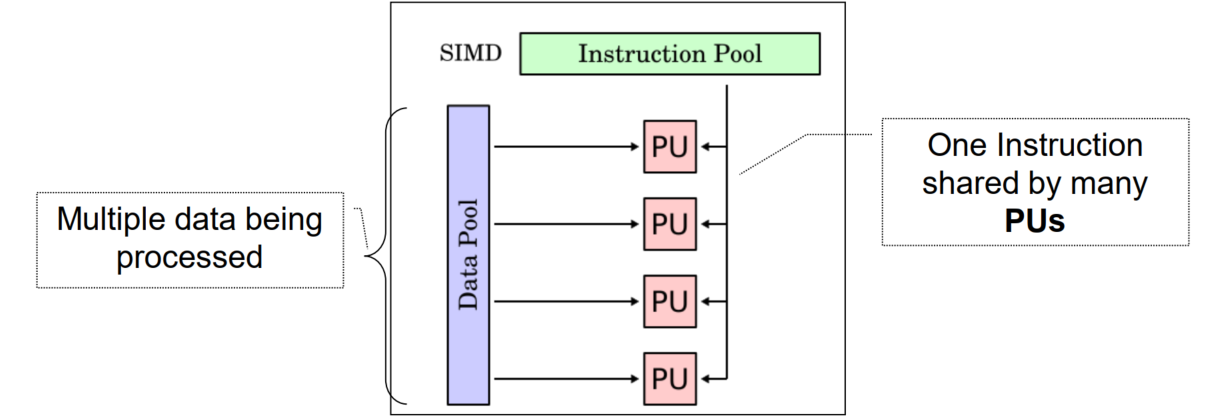
SIMD (Single insn multiple data)
One stream of instructions
One instruction multiple data
Data parallelism / Vector processor
Modern processors all have some form (Intel SSE/AVX)
An operations between 2 indexed vectors which doesn’t run into dependency problems.
e.g. GPGPUs
32 to 64 $\times$ 32-bit floating-point elements
Implicit parallelism, scalar binary with multiple instances are executed in lockstep and regrouped.
Compact: 1 instruction defines N ops (e.g. CUDA/MPI programming)
Parallel: N ops are data parallel and independent
Expressive: Regular patterns can be described
Not good for divergent executions (branching will lead to poorer performance as you can’t do stuff in unison)
Only for the
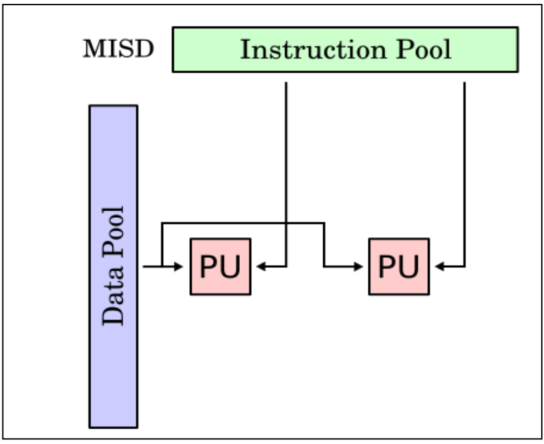
MISD (Multiple insn single data)
All instructions work on the same data at any time
No actual implementation
No useful scenario
e.g. Systolic array
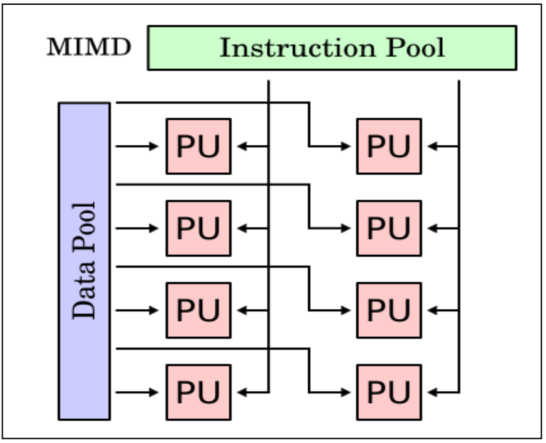
MIMD (Multiple insn multiple data)
Each PU fetches its own instruction
Each PU operates on its own data
e.g. Multiprocessor
Stream processor variants (SIMD + MIMD)
Multiprocessor + GPGPU
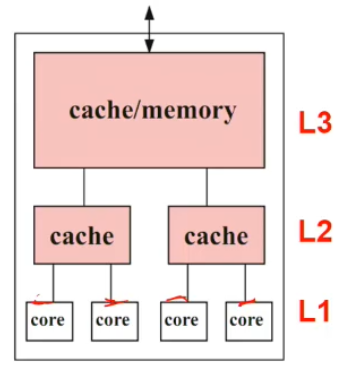
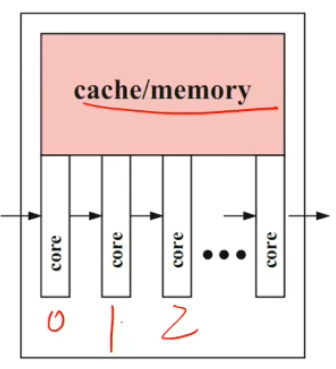
Multicore architecture
Data Design
Hierarchical design
Cache levels
Core (with own registers) at the leaves
Cache size increase from the leaves to the root
Same external memory
Pipelined design
Multiple execution cores in a pielined way.
Useful if same computation applies to long sequence of data elements
Often used with routers
Many headers to unpack/pack, one after the other (assembly line style)
Long sequence of data elements
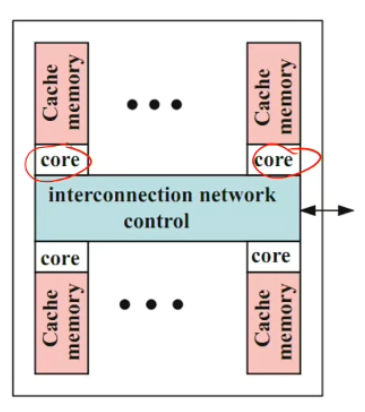
Network-based design
Failed design from Intel
interconnection very sensitive
Cores and local caches/MEM connected via interconnected network
BUT future trends indicate:
Efficient on-chip interconnects possible
Sufficient Bandwidth for data transfers between cores
Scalability
Robustness
Energy management
Reduction of memory access time (in distributed memory model)
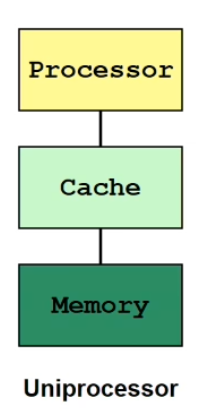
Memory Organizaiton
processor
memory module
$\ge$ caches
Caches reduce memory access latency as they
Provide high bandwidth data transfer to the CPU
I/O
Problems in memory management:
Memory latency
Time for a memory request to be serviced by memory
e.g. 100 cycles or 100nsec
Memory bandwidth
How fast can memory give you data
e.g. 20GB/s
The bottleneck nowadays
Memory bus is fully occupied, cannot give out data faster rthan the bandwidth
Distributed-Memory systems
Each node is an independent uniprocessor
Physically distributed memory module
Message passing to exchange data btwn nodes
Shared Memory System
Program accesses memory thru shared mem provider,
the shared mem architecture is encapsulated
shared variables to exchange data
We’re not talking about the underlying hardware
Do they have a shared address space.
Do they have their own local address space?
Can you directly access the memory in another node?
Pros
Cons
No partitions
Synchronization constructs required
No physical movement of data
Lack of scability (contention)
UMA: Uniform Memory Access (Time) UMA
Fetch from memory less often
Reuse data
Share data across threads
Store/reload values
DDRx the memory sped is constant, but bandwidth is improving
Cache coherence problem
Cache coherence protocol to make sure when a value in a cache is modified
the overhead of updating all of the same piece of data in cache
Shared distributed architecture
NUMA architectures can reduce memory contention in shared distriubuted memory systems
Two separate cores accessing the same memory – contention
NUMA implicitly implies multiple memory units: reduces contention
Memory consistency problem
Consistency model
A=1 from proc 0
then proc 1, can be very delayed or not
it could print before Flag = 1 or after.
while (Flag == 0);
print A when flat isn’t 0 anymore
proc1 and 2 print A
proc 2 will always print 1
always done in program order
some overhead to maintain memory consistency (e.g. proc 2)
lslide 42:
BLUE: memory system is busy getting snad sending tothe processor
GREEN: Load instruction in processor (if in cache, short time, if not, have to go to shared memory)
EVERY LOAD is going to memory
GRAY: rest of the pipeline