First GPUs were used to run shader programs, which were very customized to graphics pipeline.
Drawbacks included
Hard to transfer data
No scatter (i.e. memory write into a computed address, memory writes only into fixed addr.)
see MPI Scatter/Gather
No communication between fragments
Coarse thread synchronization
Fine-grained: possible to sync between instructions
Coarse-grained: sync only on thread termination
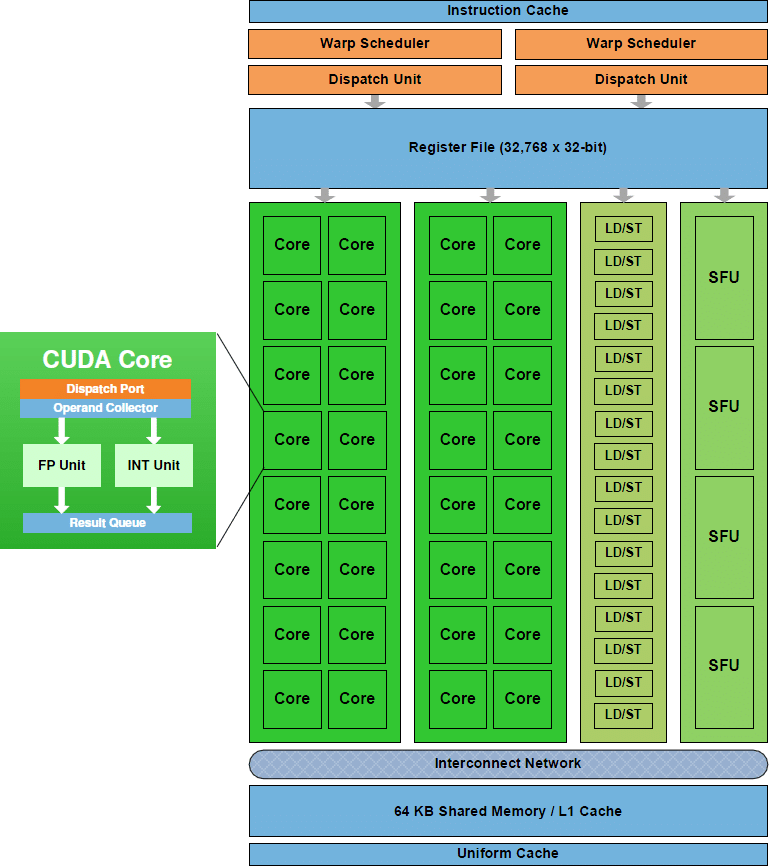
GPU Architecture
One GPU has many Streaming Multiprocessors (SMs).
Different compute capabilities have different SM architectures.
How many SMs in GPU?
How does each SM look like?
How does each core look like
How many FP, INT, SFU cores?
SFU: for special math functions e.g. $\sin$, $\cos$, $\sqrt$ etc.
Each core only do FP or only do INT operations?
Your FP cores are single precision (32b) or double (64b)?
The cores in an SM share:
Common L1 cache
Texture memory
Warp scheduler
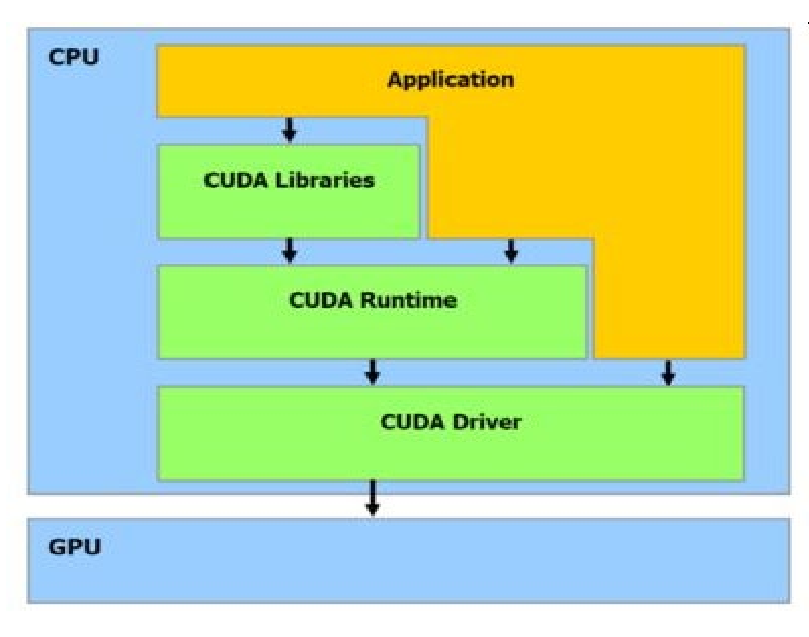
What is CUDA
Compute Unified Device Architecture (CUDA): is a general purpose programming model.
Simple C extensions
With mature software stack (high/low level access)
Launches batch threads
Load/store memory model
ISA that divides instructions into memory access (load/store) and ALU operations
CRCW: Concurrent read concurrent write
C $\rightarrow$ CUDA text intermediate representation (PTX) $\rightarrow$ device specific code (CUBIN)
CUDA C Runtime:
Minimal set of C language extensions
Kernels are C functions in src code
Built on CUDA driver API
CUDA driver API:
Low-level C API to load compiled kernels
Inspect parameters and launch
CUDA linkers
cudart (runtime library)
cuda (core library)
Definitions
Kernel: Function running on device
Older device: one kernel is executed sequentially
Modern device: kernels can run async
Host: CPU
Device: GPU
Thread: thread of execution on an SM
little creation overhead
instant switching
thread id
Block: All threads are organized in groups called blocks.
One kernel is executed by a grid of thread blocks (note this config is virtual).
Threads in a block cooperate via
Shared memory
Atomic operations
Barrier sync
Programs can thus scale transparently to any number of processors.
Threads beyond a block cannot cooperate.
Transparent scalability: HW is free to schedule threads to any processor at any time.
Kernel scales across any number of parallel multiprocessors
Several blocks can reside concurrently on an SM.
But running too many kernels on one SM will cause kernel to get stuck.
SM resources also limited
Register file
Shared memory
Thread mapping and architecture
SIMT (Single instruction multiple thread) execution model
SM creates/manages/schedules/executes threads in warps
Warp: Group of 32 parallel threads.
Start together at the same program address
But have individual program counter/register states
Block –> warps always same way
Hence block size should always be in multiples of 32.
Memory model
On-chip device memory (on the SM):
Registers
Shared memory
Const/Tex caches (aggressively cached) via L1 cache
Off-chip device memory:
Local
array variables
Global
Constant memory
Uniform access readonly
Texture memory
Spatially coherent random-access readonly data
Filtering, address clamp and wrapping
Global Memory
Coalesced access to global memory: threads in a warp (set of 32 threads) coalesced into a number of transactions.
number of transactions = number of 32-byte transactions required to service all threads of that warp.
$k$th thread accesses the $k$th word.
Strides: If thread’s global memory accesses with a stride of $k>1$ words within a warp, reduced efficiency/bandwidth
Stride of 2 words: 50% load store efficiency/bandwidth
Shared Memory
Higher bandwidth + lower latency than local/global
Equal sized memory modules (banks)
Each bank can service one address per cycle simultaneously
Bank conflict: 2 addresses trying to address the same bank in the same cycle
needs to be serialized
Each bank has 32-bit bandwidth per clock cycle (transfer 32-bits)
successive 32-bit words are assigned to successive banks.