Since 2011, by default C++ guarantees SC-DRF (default sequential consistency for data-race free programs).
However you can use atomics to
std::atomic<bool> x, y;
// ... in one thread
x.store(true, std::memory_order_seq_cst);
while (x.load(std::memory_order_seq_cst)) {};
// ... in another thread
while (!x.load(std::memory_order_seq_cst)) {};
x.store(false, std::memory_order_seq_cst);
As can be seen above atomics can take in an optional memory-ordering argument.
enum std::memory_order {
memory_order_seq_cst, // default
memory_order_relaxed,
// LOAD ACQUIRE - STORE RELEASE
memory_order_release, // store ops only
memory_order_acquire, // load ops only
// RMW ops can do all of the above plus
memory_order_acq_rel,
}
Useful tool to generate memory order graph: [http://svr-pes20-cppmem.cl.cam.ac.uk/cppmem/]
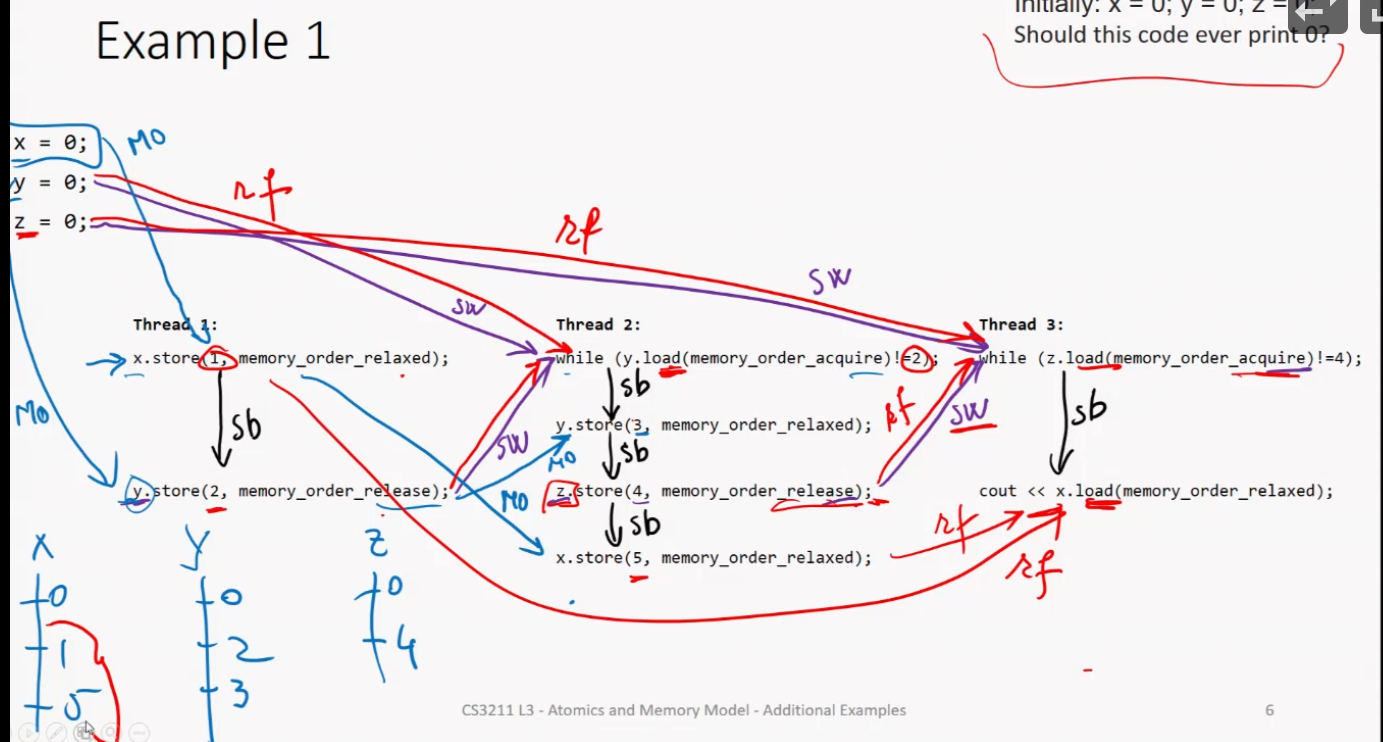
(Program order) If eval A is sequenced before B, then resp(A) < inv(B).
(Object order) Given atomic store on x by thread 1,
and atomic load on x by thread 2 reads the value written by thread 1 or by any thread after,
then the store synchronizes-with the load.
Between atomic load and store operations,
W tagged with either SC or Acq-Rel or RelR tagged with either SC or Acq-Rel or AcqR reads value stored by
WW (i.e. W can be the original value)
rmw where rmw’s read detects value stored by W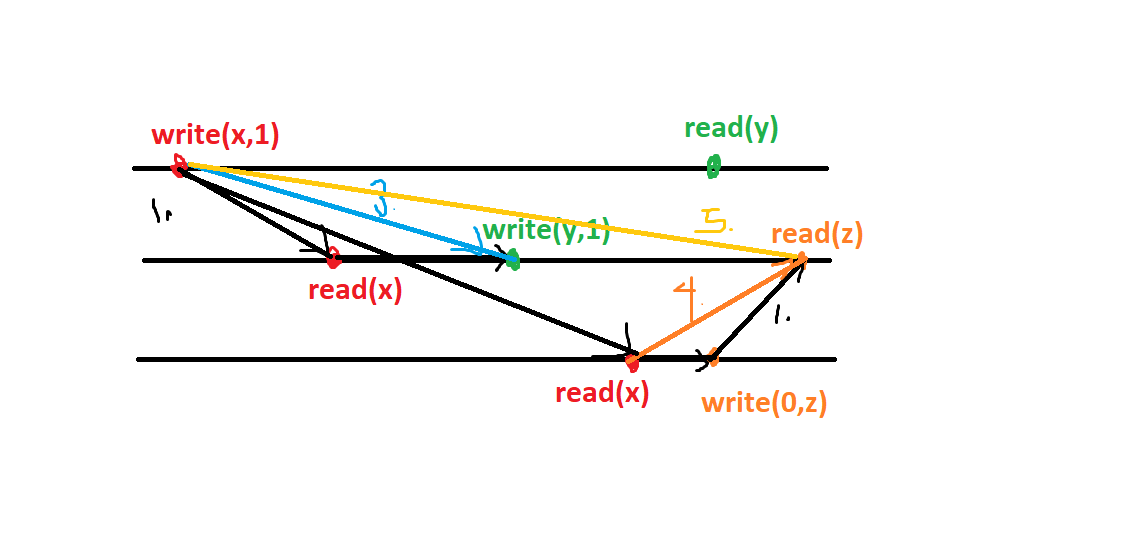
The side effect A on a scalar M is visible to B on M if
Object order of writes
memory_order_seq_cstSequential Consistency (SC) guarantees that all threads must see the same process order.
If the target architecture is a weakly ordered machine, SC incurs penalty as extra insns have to be inserted.
Sequential orddering:
Non-SC orderings only agree on the modification order of each object but not the global order.
Relaxed ordering only guarantees that all threads will see the same object order.
For a variable v,
4 into v5 into vv it can get either 4 or 5.
v == 5v afterwards,v == 4If a thread A does an atomic store tagged memory_order_release
and a thread B does an atomic load tagged memory_order_acquire
all ops before the thread A’s atomic store op become visible to thread B.
This includes non-atomic operations!!
std::atomic (or volatile)std::memory_order_seq_cststd::memory_order_acq_relstd::memory_order_relaxedseq_cst. Specific single total order requires SC.relaxed don’t care aboutacq_relSC guarantees that there is a fixed total ordering of all operations across all variables that all the threads see.
Acquire Release not longer guarantees this total ordering across different vars seen by each thread may be different.
Attempt to create DAG; if cycles are formed then deadlock exists.
Relaxed: Operations are not reordered by the compiler, but the processor relaxes constraints on that level.