Different configs of the vocal tract shapes airstream
Reading a waveform
x-axis: time
y-axis: air pressure
vowels have more variation in air pressure (bigger amplitude)
Air pressure –> Recognition in human ears
Ear’s first response is to break down into different frequencies.
Extract the frequency components of speech sounds
Linguists don’t use waveforms because they don’t show frequencies.
Reading a spectrogram
x-axis: time
y-axis: frequency (Hz)
color: darker = higher amplitude (air pressure) at the frequency
Speech sounds have different frequency profiles.
Which is why spectrograms are more useful for linguists, as it is easier to
deduce articulatory profiles.
You need the waveform to get the spectrogram.
Spectral Analysis
Taking 1s of time from the waveform and calculating the frequencies
based on the period of waves. and then stacking it in a box.
Sound can have more than one frequency! In fact all sounds except
pure tone of a tuning fork has complex structure.
Speech sounds contains different number of pitches at the same time.
Pitch
High/low pitch $\approx$ rate of vibration of the vocal folds
Vocal folds’ Rate of vibration = Fundamental frequency (F0)
It is our only sensation of pitch (its the only pitch we are constantly aware of.)
it isn’t in the spectrogram.
Overtone pitches or Formants
Depend on the shape of the vocal tract, not the vibration
Cannot be heard separately as a distinguishable pitch
dependent on the shape of the vocal tract
different vocal tract configurations will result in different formant values
Formants are actually echoes in our vocal tract.
Energy is amplified at certain areas and dampened at others
We count from the bottom (lowest frequencies) as 1
First, second and third formants
Formant values are definitely always different, as everyone has a different vocal tract.
High/low pass filter
only allow high/low frequencies to pass through
fricatives: higher frequencies
vowels: lower frequencies
Yanny/Laurel:
Older people were hearing one thing (as we age our ears get less sensitive to higher frequencies)
Younger people were hearing another
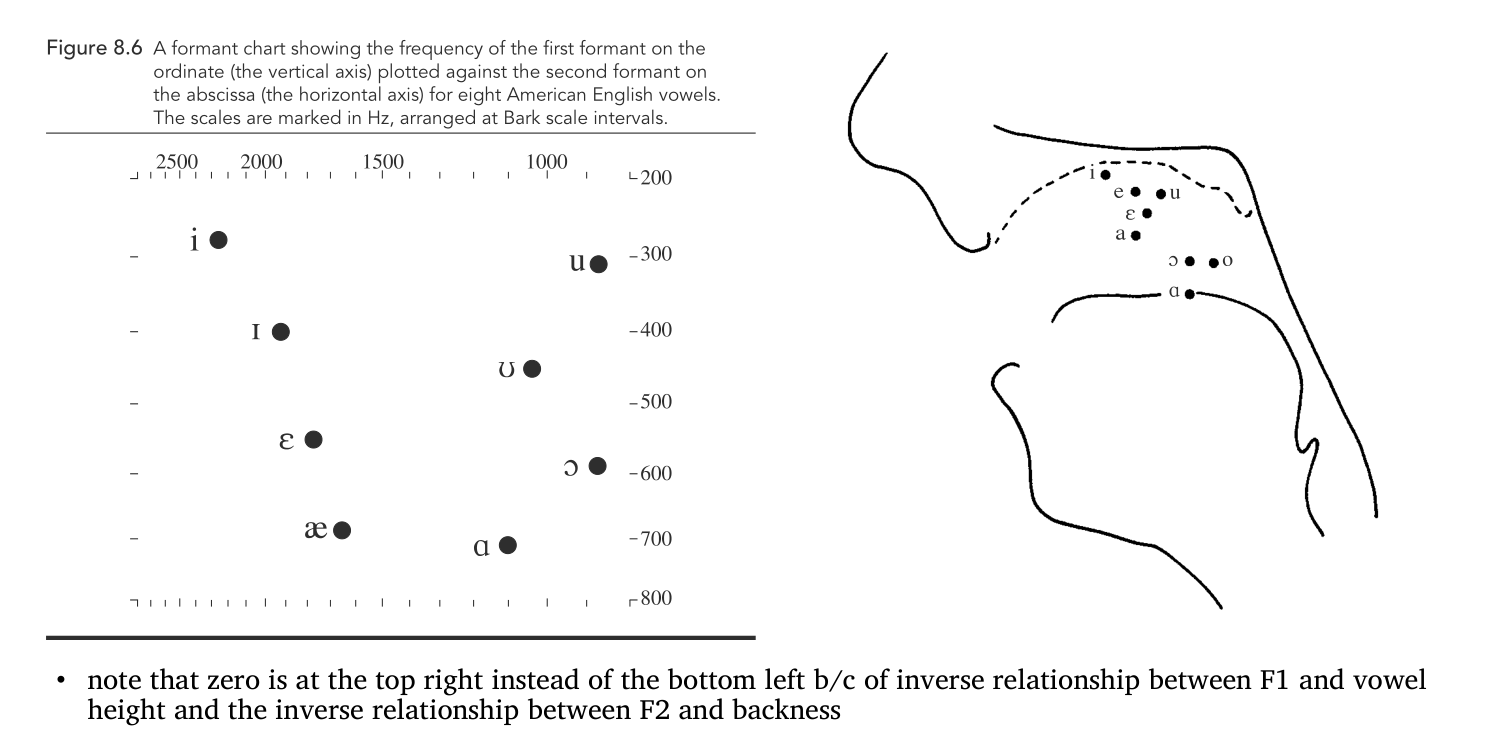
Vowels
First formant (F1)
[i, ɪ, ɛ, æ], [u, ʊ, ɔ, ɑ]: From the lowest F1 to the highest
High vowels are associated with low F1 [i]
Low vowels are associated with high F1 [æ]
Second formants (F2)
Front vowels have higher F2 than back vowels
Front High vowels are associated with high F2 [i]
Front Low vowels are associated with lower F2 [æ]
implies that [i] is more front than [æ]
These first two formants are showing the following.
The ppl who first created the vowel chart thoguht they were mapping the tongue placement
BUT it actually represents the acoustics (frequency profiles) of the sounds.
The absolute formant values differ
Vowels look relatively clear on a chart, but what about consonants??
Diphthongs: The formant will morph throughout
Consonants
Consonants convey the quality by their effects on adjacent vowels.
Oral closure causes lowering of the first formant (which is why higher vowels have lower F1s.)
Plosives/Stops
(initial) SILENCE -> SHARP SPIKE
(mid/end) SHARP SHUTDOWN
When preceded by a stop, vowel’s F1 rises at the start
When followed by a stop, the vowel’s F1 falls
Closing your mouth brings down the F1.
Transitional cues are marked on the vowel
Bilabial: Has lower F2 and F3 at the transition
Dental/alveolars: Raises F2/F3 at the boundary
Velars: Cause F2/F3 to come together (velar pinch)
The ear doesn’t register silence. So it makes use of the transitional cues
Voiced sounds: faint striations near the baseline for every single voiced sound (including vowels).
Most English speakers have no voice bars for initial “voiced” stops
Sharp spike after silence is a stop
initial voiced/unvoiced is thus differentiated by aspiration
Voice onset time (sharp spike corresponding to the release burst)
Fricatives
Looks like random noise on the spectrogram
Releasing air from the glottis
Dental/Alveolar/Post-alveolar is very easier to identify for fricatives:
[s,z] are noisier than [f, θ]
Very high frequency (going into 8000Hz)
Voiced: similar to voiceless counterparts but have voice bars
Approximants
looks similar to vowels
rapidly changing
[l] -
[ɹ] - initially low F2/F3 that rises steeply, F3 steepest
[w] - initially low F2/F3 that rises steeply, F2 steepest
[j] - initially high F2/F3 that falls steeply, F3 steepest